Concepts Overview
The following concepts are important to understand for configuring and managing synchronization:
Data Source
A data source represents the connection to a backend which plays the role of either a source or target endpoint for synchronization. Data Sources are configured from the Control Panel > Setup > Data Catalog > Data Sources.
Capture Connector
Agents manage connectors which includes deploying, stopping/suspending and starting them as needed.
A connector is a component that captures changes from data sources. Capture connectors are configured as part of the pipeline configuration process. Capture connectors associated with the RadiantOne Universal Directory (HDAP) stores or persistent caches are automatically configured when the stores are used as a source in a pipeline. Capture connectors for all other data sources require configuration. Capture connectors are configured from the Main Control Panel > Global Sync tab. Select a topology on the left and then select Configure next to the pipeline.
There are no apply connectors to configure or manage. Changes are propagated through the RadiantOne virtualization layer to the destination.
Queue
RadiantOne Global Sync relies on queues for guaranteed delivery of messages. Queues are a special kind of store managed in the RadiantOne Universal Directory below the cn=queue and cn=dlqueue root naming contexts. Every synchronization pipeline has its own queue below the cn=queue and cn=dlqueue naming contexts identified by the pipelineID. Messages are added into the queues by the capture connectors and retrieved from the queues by the sync engine. Both cn=queue and cn=dlqueue are hidden root naming contexts, so if you want to view them, you must search for them. The Main Control Panel > Directory Browser tab can be used. An example is shown below.

Message time-to-live
Messages remain in the queue until they are either picked up by the sync engine, or the message time-to-live has been reached (default of 3 days). Message time-to-live is configured in the "Changelog and Replicationjournal Max Age" property from the Main Control Panel > Settings > Logs > Changelog.

Apply connector
The apply connector applies changes to the destination object(s). Once the transformation component is successfully configured, the Apply connector automatically starts. There is no configuration of the apply connector. The apply process leverages the virtualization of the target as depicted in this figure, meaning that all changes are sent to the RadiantOne service, directed to the branch in the namespace where the virtual view of the target has been mounted.
Sync Engine
The Sync Engine processes the transformations and sends the changed entries to the destination.
Transformation
A transformation describes how changes on source entries should be translated into entries for a destination. The transformation component can consist of rules, or attribute mappings and/or scripting to accommodate more complex logic. When both attribute mappings and a script are used, the attribute mappings are applied first. When rules are used, the attribute mappings and scripts options are not used. The table below provides some general guidance on choosing which option to use when configuring transformation.
Attribute Mappings (Low code/no code experience, minimum flexibility) | Script (Max flexibility, but must know how to code in Java) | Rules (Low code/no code experience, medium flexibility) | |
|---|---|---|---|
Source and target attribute (names) are the same and mappings are simple | ✔ | ||
Lookups or other complex logic (conditions or actions) is required and you are comfortable with using java to code the entire logic | ✔ | ||
Complex conditions or actions are required and you do not want to code in java | ✔ |
Attribute mappings
Attribute mappings indicate how data should be transformed before propagating the event to the destination. This could involve a simple 1-to-1 mapping of a value, setting a constant value, or computing a new value. Each sync pipeline can be associated with one or more attribute mappings. Typically, each type of object (e.g. group, user) you are synchronizing has an Attribute Mapping associated with it.
See Attribute mappings for configuration steps.
Script
When attribute mappings are insufficient to achieve your business logic, you can use Java scripting (or Rules). This is helpful when lookups or other complex logic is required and the capabilities of the attribute mappings and rules options are insufficient. The Main Control Panel > Global Sync tab provides an interface for configuring the script (with some support for basic syntax checking).
See Script for configuration steps.
Rules-based Transformation
The Rules-based Transformation option offers a default event-based template that allows for configuring conditions and actions for determining synchronization logic. This offers more customized synchronization logic than simple attribute mappings without having to write code. If Rules are used, you do not define separate attribute mappings or scripts.
Rules are packaged as a set and are associated with a single source entry object type/class. You will create a rule set for every source object class that you want to detect changes on. A rule categorizes a set of conditions in a source system and the set of actions that must be taken in a target system if the conditions are met. For each rule, conditions and actions are defined. Many rules can be defined for a transformation and the default behavior is to evaluate all rules in the order in which they are defined.

See Rules for configuration steps.
Conditions
Rules consist of one or more conditions. A condition is an expression that involves a variable, an operator, and a value. Conditions are evaluated to determine if activity in the source should be propagated as action(s) to a target. If multiple conditions are defined, they are evaluated in order from top down. The main operator to apply to the entire set of conditions can be either an AND or an OR. Although you can have many nested conditions leveraging both AND or OR operations below the main operator. For example, the conditions shown in the screen below indicate a main AND operator even though the list of expressions involves nested OR conditions.
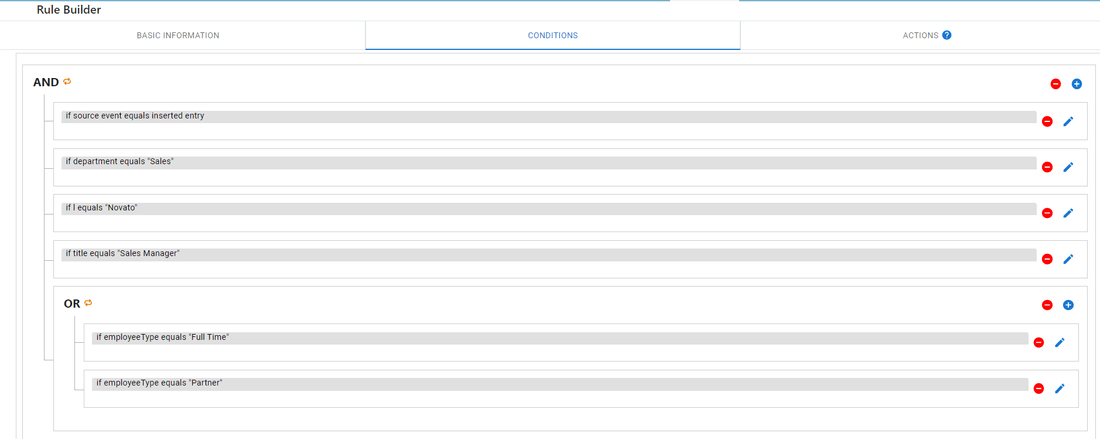
The example conditions shown above would be evaluated as follows.
If a new entry is inserted into the source system, and if the department for the new entry equals "Sales", and if the l attribute value equals "Novato" and the title attribute for the new entry equals "Sales Manager" and if at least one of the expressions located below the OR branch evaluates to true (if employeeType for the new entry equals "Full Time" or "Partner"), then the actions defined for the rule are executed. If any conditions located in the AND branch evaluate to false, or if all conditions in the OR branch evaluate to false, then the actions are not executed.
When defining a condition, the expression can be evaluated based on many different operators. The possible operators are shown below.

Variables
A variable can be defined to store a temporary value and used in a rule condition to apply a computation or more advanced logic. If you need to manipulate a source attribute, or calculate a value to use as part of your rule conditions, a variable should be defined. These variables are local to a single Rule Set of a given topology. A variable can be set to a constant value, be populated from another variable (local or source attribute), or be computed based on a function.
You can also configure one or more conditions that dictate the context in which the variable is populated with the configured value. If no conditions are defined, the local variable value is populated based on the configuration in the "Values" setting: constant value, the source attribute value, or the function. If conditions are required to determine how the variable is populated, they can be based on a Source Attribute, Source Event, Attribute Event, or Rule Variable. A brief description and example of each
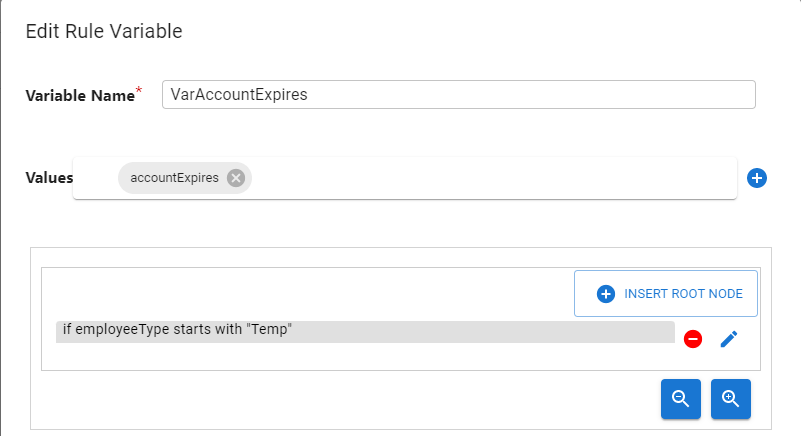
- Source Attribute – a condition can be based on the value of a source attribute. Select a source attribute name (a list of attributes defined in the source schema is displayed for you to select from), enter a value of the attribute to condition the comparison, an operator (e.g.
equals,doesn't equal,is greater than, etc.) and a comparison type (e.g. case-sensitive, ignore case, numeric, regular expression, or binary). The example Rule Variable below indicates that the variable namedVarAccountExpiresis set from the source attribute namedaccountExpireswhen the source attributeemployeeTypestarts with a value of"Temp".
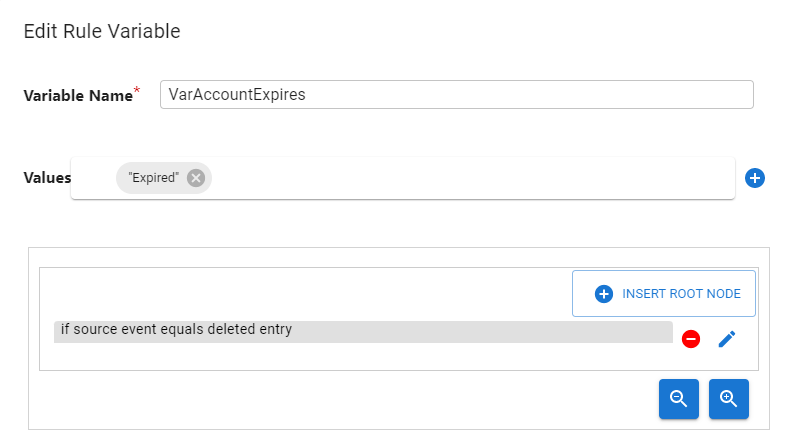
- Source Event – a source event is defined as an update to an entry, inserting a new entry, deleting an entry or moving an entry (
modRDNoperation in an LDAP directory). The condition can be defined as eitherequalsornot equals. An example condition would beSource EventequalsNew Entry. The example Rule Variable below indicates that the variable namedVarAccountExpiresis set with a constant value of"Expired"when the entry in the source is deleted.
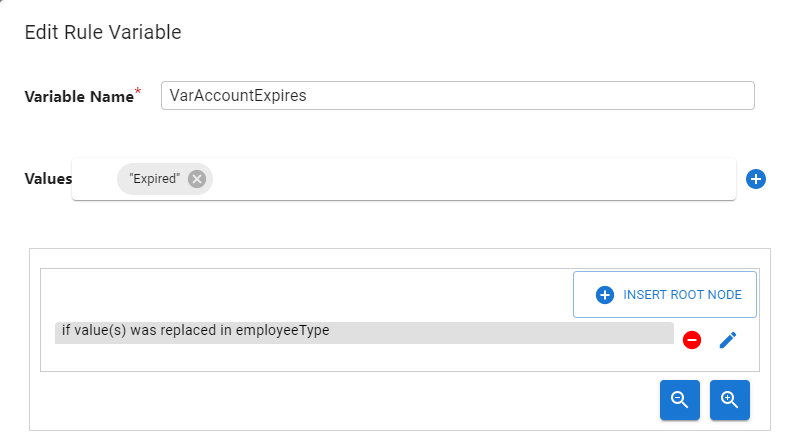
- Source Attribute Event - a condition can be based on the type of event on a source attribute. To define a condition based on a source attribute event, you must select the type of event you are interested in ("Value(s) was added", "Value(s) was NOT added", "Value was deleted", "Value was NOT deleted", "Value(s) was replaced", "Value(s) was NOT replaced"), and a source attribute name (a list of attributes defined in the source schema is displayed for you to select from). The example Rule Variable below indicates that the variable named
VarAccountExpiresis set with a constant value of"Expired"when the value of the sourceemployeeTypeattribute is replaced.
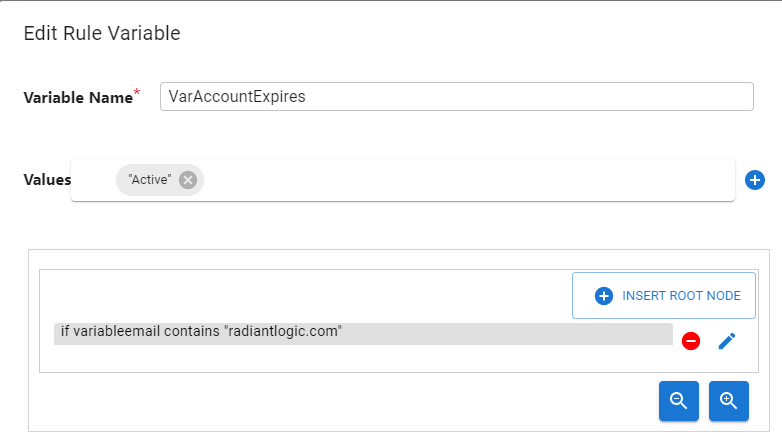
- Rule Variable – a condition can be based on a value of another rule variable. Select a variable (a list of defined local variables is available for you to select from), enter a value of the local variable to condition the comparison, an operator (e.g.
equals,doesn't equal,is greater than, etc.) and a comparison type (e.g. case-sensitive, ignore case, numeric, regular expression, or binary). The example Rule Variable below indicates that the variable namedVarAccountExpiresis set to a value of"Active"when the local variable namedvariableemailcontains"radiantlogic.com".
Actions
Rules consist of one or more actions. Actions are performed because of conditions being met. If conditions are met, all actions configured for the rule are executed. The possible actions that can apply to a rule are:
- Abort – decide not to propagate the changes to the target system.
- Apply Target Attribute Mappings – attribute mappings dictate how input value(s) must be transformed in preparation to apply to a target system. Some input value(s) may require little to no transformation while others may require advanced computations and logic. Existing attribute mappings can be re-used, or new attribute mappings can be defined.
- Custom Function – Allows you to create a custom function or call an existing function. This offers flexibility to add your own code to accommodate situations where the default actions are insufficient.
Topology
The naming and graphical representation of a set of objects participating in a synchronization process is known as a topology.
Pipeline
The synchronization flow(s) in a topology are grouped and depicted as pipelines. A topology can consist of one or more synchronization pipelines. Pipelines are auto-generated when the topology is created. You cannot manually create your own pipelines.
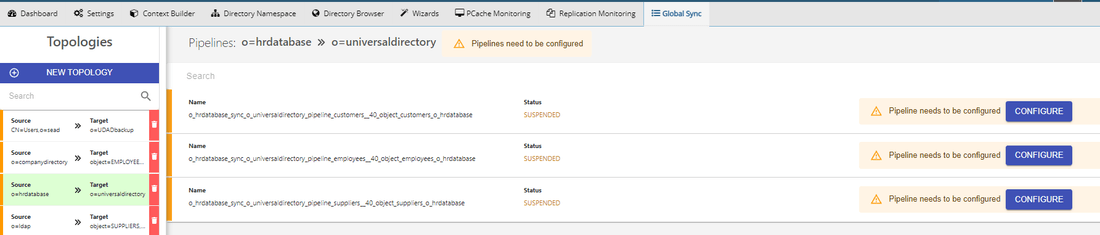
An example of a topology with a single auto-generated pipeline is shown below:

An example of a topology with multiple auto-generated pipelines is shown below:
Pipeline ID
The pipeline ID is required for a variety of scenarios. A few examples are shown below.
Example | Description |
|---|---|
| REST command for replaying messages from a dead letter queue. |
| REST command for running an upload from command line. |
| Locating connector logs associated with the pipeline. You can view and download the connector log from the Environment Operations Center. |
You can find the pipeline ID from the Main Control Panel > Global Sync tab.
Select the topology and hover over the name property of the pipeline. An example is shown below.

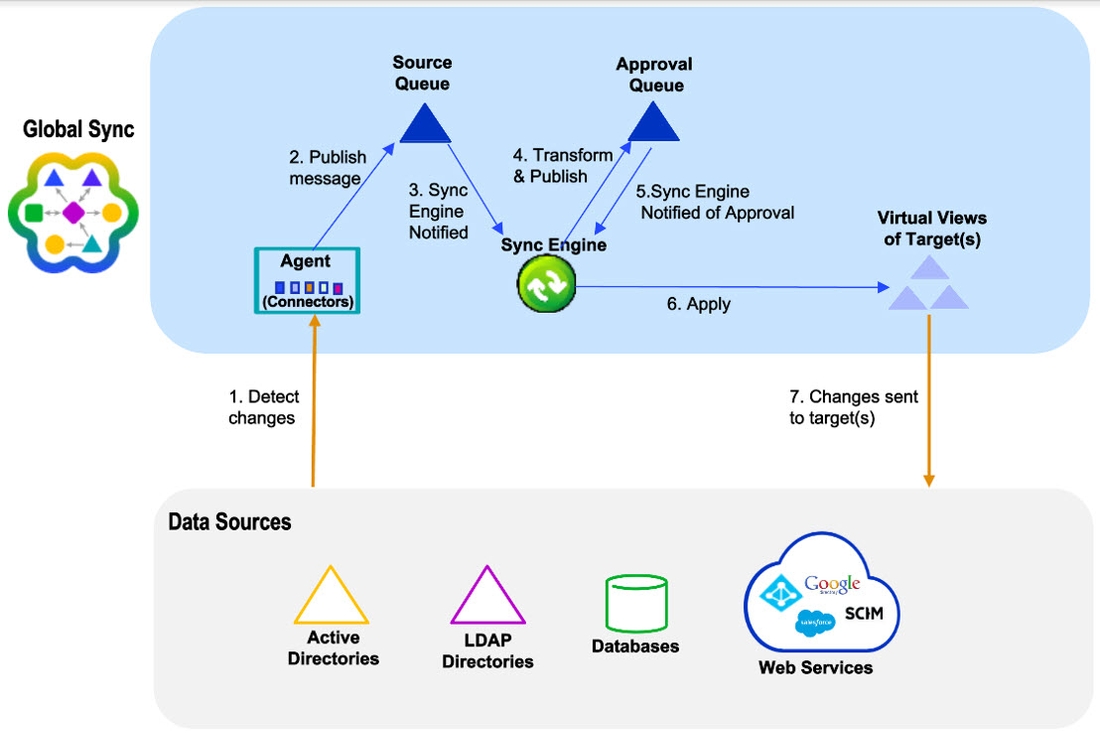
Approvals
For synchronization pipelines that use rules-based transformation, you can configure source events to require an extra manual approval step prior to the change being sent to target systems. The “Require Approval” option is used for this purpose and dictates that certain events must be approved by a specified set of users before they are applied to target systems. When a change associated with a rule that requires approval is detected in a source, the instance is published into the approvals queue and awaits action. All users that are required to act on the event, must be assigned to the Approvers role and use the Approvals application to act on the event before it expires. If the change is approved, it is processed, removed from the queue and published to the target(s). If it is rejected, the change is aborted and the message is deleted from the queue. A high-level diagram of the process is shown below.
The approval queue is automatically created as needed.