Persistent Cache Oveview
Persistent cache is the cache image stored on disk. With persistent cache, the RadiantOne service can offer a guaranteed level of performance because the underlying data source(s) do not need to be queried and once the server starts, the cache is ready without having to “prime” with an initial set of queries. Also, you do not need to worry about how quickly the underlying data source can respond. What is unique about the persistent cache is if the RadiantOne service receives an update for information that is stored in the cache, the underlying data source(s) receives the update, and the persistent cache is refreshed automatically. In addition, you have the option of configuring real-time cache refreshes which automatically update the persistent cache image when data changes directly on the backend sources. For more details, please see Refreshing the Persistent Cache.
If you plan on caching (either entry memory cache or persistent cache) the branch in the tree that maps to an LDAP backend, you must list the operational attributes you want to be in the cache as “always requested”. Otherwise, the entry stored in cache would not have these attributes and clients accessing these entries may need them.
Persistent Cache Disk Space Requirements
Initialization of a persistent cache happens in two phases. The first phase is to create an LDIF formatted file of the cache contents (if you already have an LDIF file, you have the option to use this existing file as opposed to generating a new one). The second phase is to initialize the cache with the LDIF file. After the first phase, RadiantOne prepares the LDIF file to initialize the cache. Therefore, you need to consider at least these two LDIF files and the amount of disk space to store the entries in cache.
Best practice would be to take four times the size of the LDIF file generated to determine the disk space that is required to initialize the persistent cache. For example, lab tests have shown 50 million entries (1KB or less in size) generates an LDIF file approximately 50 GB in size. So total disk space recommended to create the persistent cache for this example would be 200 GB.
Initializing Persistent Cache
Persistent cache should be initialized during off-peak hours, or during scheduled downtime, since it is a CPU-intensive process and during the initialization queries are delegated to the backend data sources which might not be able to handle the load.
When initializing persistent cache, two settings you should take into consideration are paging and initializing cache from an encrypted file. These options are described in this section.
If you are using real-time refresh, make sure the cache refresh components are stopped before re-initializing or re-indexing a persistent cache.
Using Paging
Depending on the complexity of the virtual view, building the persistent cache image can take some time. Since the internal connections used by RadiantOne to build the persistent cache image are subject to the Idle Connection Timeout server setting, the cache initialization process might fail due to the connection being automatically closed by the server. To avoid cache initialization problems, it is recommended to use paging for internal connections. To use paging:
-
Navigate to the Main Control Panel > Settings tab > Server Front End > Supported Controls.
-
On the right, check the option to Enable Paged Results.
-
Click Save.
-
Navigate to the Main Control Panel > Settings tab > Server Backend > Internal Connections (requires Expert Mode).
-
On the right, check the option for Paged Results Control, page size: 1000.
-
Click Save.
Supporting Zipped and Encrypted LDIF Files
If you are initializing persistent cache using an existing LDIFZ file, the security key used in RadiantOne (for attribute encryption) where the file was exported must be the same security key value used on the RadiantOne server that you are trying to import the file into.
If you are creating a new LDIF file to initialize the persistent cache, you have the option to use an LDIFZ file which is a zipped and encrypted file format. This ensures that the data to be cached is not stored in clear in files required for the initialization process.
To use this option, you must have an LDIFZ encryption key configured. The security key is defined from the Main Control Panel > Settings Tab > Security > Attribute Encryption section.
Once the security key has been defined, check the option to “Use .ldifz (zipped and secure format).
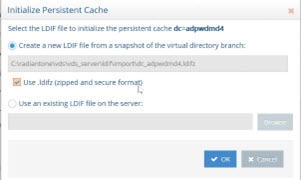
Figure 2.4: Using LDIFZ File to Initialize Persistent Cache
Options for Refreshing the Persistent Cache
There are four categories of events that can invoke a persistent cache refresh. They are:
-
When changes occur through RadiantOne.
-
When changes occur outside of RadiantOne (directly on the backend source).
-
Scheduling a periodic refresh of the persistent cache.
Each is described below.
Changes Occurring Through RadiantOne
If RadiantOne receives an update for an entry that is stored in a persistent cache, the following operations occur:
-
The entry in persistent cache is “locked” pending the update to the underlying source(s).
-
The underlying source(s) receives the update from RadiantOne.
-
Upon successful update of the underlying source(s), RadiantOne updates the entry in the persistent cache.
-
The modified entry is available in the persistent cache.
Real Time Cache Refresh Based on Changes Occurring Directly on the Backend Source(s)
When a change happens in the underlying source, connectors capture the change and send it to update the persistent cache. The connectors are managed by agents built into RadiantOne and changes flow through a message queue for guaranteed message delivery. The real-time refresh process is outlined below.
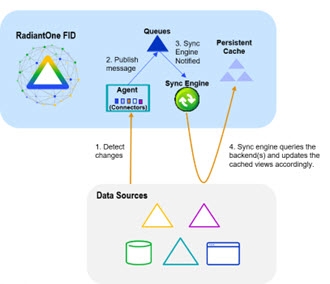
Figure 2.5: Persistent Cache Refresh Architecture
Persistent Cache Refresh Agents are started automatically once a persistent cache with real-time refresh is configured. Agents can run on any type of RadiantOne cluster node (follower or leaders) and there is only one agent running at any given time in a RadiantOne cluster. The agent doesn't consume a lot of memory, and they are not CPU-intensive, so there is no point in running multiple processes to distribute connectors on multiple nodes. One agent is enough per cluster and makes things simpler.
This type of refresh is described as “Real-time” in the Main Control Panel > Directory Namespace > Cache settings > Cache Branch > Refresh Settings tab (on the right). This is the recommended approach if a real-time refresh is needed.
Periodic Refresh
In certain cases, if you know the data in the backends does not change frequently (e.g. once a day), you may not care about refreshing the persistent cache immediately when a change is detected in the underlying data source. In this case, a periodic refresh can be used.
If you have built your view in either the Context Builder tab or Directory Namespace Tab, you can define the refresh interval after you’ve configured the persistent cache. The option to enable periodic refresh is on the Refresh Settings tab (on the right) for the selected persistent cache node. Once the periodic refresh is enabled, configure the interval using a CRON expression. Click the Assist button if you need help defining the CRON expression.
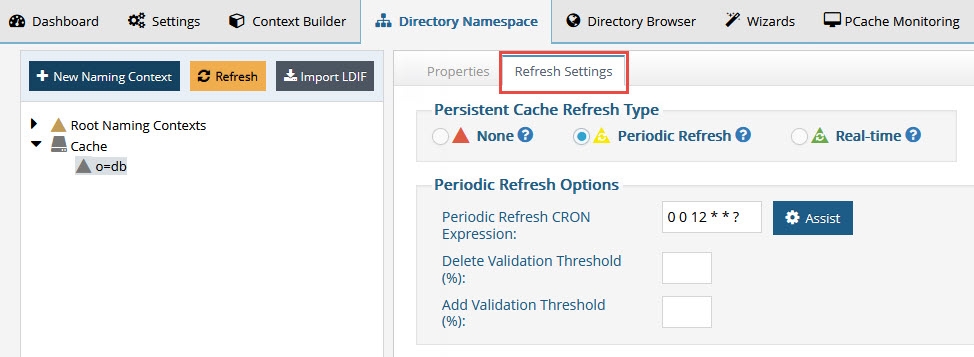
Figure 2.6: Periodic Cache Refresh Settings
During each refresh interval, the periodic persistent cache refresh is performed based on the following high-level steps:
- RadiantOne generates an LDIF formatted file from the virtual view (bypassing the cache).
If a backend data source is unreachable, RadiantOne attempts to re-connect one more time after waiting 5 seconds. The number of retries is dictated by the maxPeriodicRefreshRetryCount property defined in /radiantone/<version>/<clusterName>/config/vds_server.conf in ZooKeeper.
-
(Optional) If a validation threshold is defined, RadiantOne determines if the threshold defined has been exceeded. If it has, the persistent cache is not refreshed during this cycle.
-
RadiantOne compares the LDIF file generated in step 1 to the current cache image and applies changes to the cache immediately as it goes through the comparison.
The periodic persistent cache refresh activity is logged into periodiccache.log. This file can be viewed and downloaded from Server Control Panel > Log Viewer. For details on this log, see the Logging and Troubleshooting Guide.
The rebuild process can be very taxing on your backends, and each time a new image is built you are putting stress on the data sources. This type of cache refresh deployment works well when the data doesn’t change too frequently and the volume of data is relatively small.
Configuring Persistent Cache with Periodic Refresh
Review the section on periodically refreshing the cache to ensure the persistent cache is updated to match your needs. If you plan on refreshing the cache image periodically on a defined schedule, this would be the appropriate cache configuration option. This type of caching option leverages the internal RadiantOne Universal Directory storage for the cache image.
To configure persistent cache with Periodic refresh
-
On the Directory Namespace tab of the Main Control Panel, click the Cache node.
-
On the right side, browse to the branch in the RadiantOne namespace that you would like to store in persistent cache and click OK.
-
Click Create Persistent Cache. The configuration process begins. Once it completes, click OK to exit the window.
-
Click the Refresh Settings tab.
-
Select the Periodic Refresh option.
-
Enter the CRON expression to define the refresh interval.
-
(Optional) Define a Delete Validation Threshold.
-
(Optional) Define an Add Validation Threshold.
-
Click Save.
-
Click Initialize to start the initialization process.
There are two options for initializing the persistent cache: Creating a new LDIF file or initializing from an existing LDIF file. Each is described below.
Create an LDIF from a Snapshot
If this is the first time you’ve initialized the persistent cache, then you should choose this option. An LDIF formatted file is generated from the virtual view and then imported into the local RadiantOne Universal Directory store.
Initialize from an Existing LDIF File
If you’ve initialized the persistent cache before and the LDIF file was created successfully from the backend source(s) (and the data from the backend(s) has not changed since the generation of the LDIF file), then you can choose to use that existing file. The persisting of the cache occurs in two phases. The first phase generates an LDIF file with the data returned from the queries to the underlying data source(s). The second phase imports the LDIF file into the local RadiantOne Universal Directory store. If there is a failure during the second phase, and you must re-initialize the persistent cache, you have the option to choose the LDIF file (that was already built during the first phase) instead of having to re-generate it (as long as the LDIF file generated successfully). You can click browse and navigate to the location of the LDIF. The LDIF files generated are in <RLI_HOME><instance_name>\ldif\import.
If you have a large data set and generated multiple LDIF files for the purpose of initializing the persistent cache (each containing a subset of what you want to cache), name the files with a suffix of “_2”, “_3”…etc. For example, let’s say the initial LDIF file (containing the first subset of data you want to import) is named cacheinit.ldif. After this file has been imported, the process attempts to find cacheinit_2.ldif, then cacheinit_3.ldif…etc. Make sure all files are located in the same place so the initialization process can find them.
After you choose to either generate or re-use an LDIF file, click Finish and cache initialization begins. Cache initialization is launched as a task and can be viewed and managed from the Tasks Tab in the Server Control Panel associated with the RadiantOne leader node. Therefore, you do not need to wait for the initialization to finish before exiting the initialization window.
After the persistent cache is initialized, queries are handled locally by the RadiantOne service and no longer be sent to the backend data source(s). For information about properties associated with persistent cache, please see Persistent Cache Properties.
Periodic Refresh CRON Expression
If periodic refresh is enabled, you must define the refresh interval in this property. For example, if you want the persistent cache refreshed every day at 12:00 PM, the CRON expression is: 0 0 12 1/1 * ? * Click Assist if you need help defining the CRON expression.
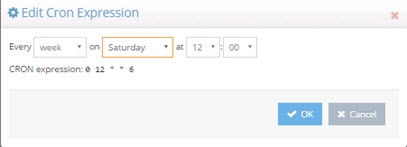
Figure 2.7: CRON Expression Editor
Delete Validation Threshold
For details on how the periodic persistent cache refresh process works, see Periodic Refresh.
You can define a threshold to validate the generated LDIF file/image prior to RadiantOne executing the cache refresh process. The threshold is a percentage of the total entries.
To define a granular threshold for delete operations, indicate the percentage in the Delete Validation Threshold. For example, if Delete Validation Threshold contains a value of 50, it means if the generated LDIF image contains at least 50% fewer entries than the current cache image, the periodic persistent cache refresh is aborted for the current refresh cycle.
If a validation threshold is configured, the threshold is checked.
Add Validation Threshold
For details on how the periodic persistent cache refresh process works, see Periodic Refresh.
You can define a threshold to validate the generated LDIF file/image prior to RadiantOne executing the cache refresh process. The threshold is a percentage of the total entries.
To define a granular threshold for add operations, indicate the percentage in the Add Validation Threshold. For example, if Add Validation Threshold contains a value of 50, it means if the generated LDIF image contains 50% more entries than the current cache image, the periodic persistent cache refresh is aborted for the current refresh cycle.
Configuring Persistent Cache with Real-Time Refresh
If you plan on automatically refreshing the persistent cache as changes happen on the backend data sources, this would be the recommended cache configuration option. This type of caching option leverages the RadiantOne Universal Directory storage for the cache image.
If you choose a real-time refresh strategy, there are two terms you need to become familiar with:
-
Cache Dependency – cache dependencies are all objects/views related to the view that is configured for persistent cache. A cache dependency is used by the cache refresh process to understand all the different objects/views that need to be updated based on changes to the backend sources.
-
Cache Refresh Topology – a cache refresh topology is a graphical representation of the flow of data needed to refresh the cache. The topology includes an object/icon that represents the source (the backend object where changes are detected from), the queue (the temporary storage of the message), and the cache destination. Cache refresh topologies can be seen from the Main Control Panel > PCache Monitoring tab.
Cache dependencies and the refresh topology are generated automatically during the cache configuration process.
If you have deployed multiple nodes in a cluster, to configure and initialize the persistent cache, you must be on the current RadiantOne leader node. To find out the leader status of the nodes, go to the Dashboard tab > Overview section in the Main Control Panel and locate the node with a yellow triangle icon.
To configure persistent cache with real-time refresh:
-
Go to the Directory Namespace Tab of the Main Control Panel associated with the current RadiantOne leader node.
-
Click the Cache node.
-
On the right side, browse to the branch in the RadiantOne namespace that you would like to store in persistent cache and click OK.
For proxy views of LDAP backends, you must select the root level to start the cache from. Caching only a sub-container of a proxy view is not supported.
-
Click Create Persistent Cache. The configuration process begins. Once it completes, click OK to exit the window.
-
On the Refresh Settings tab, select the Real-time refresh option.
If your virtual view is joined with other virtual views you must cache the secondary views first. Otherwise, you are unable to configure the real-time refresh and will see the following message. A Diagnostic button is also shown and provides more details about which virtual views require caching.
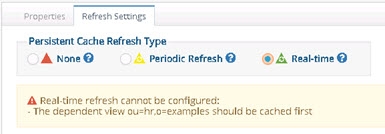
Figure 2.8: Caching secondary views message
-
Configure any needed connectors. Please see the section titled Configuring Source Connectors for steps.
-
Click Save.
-
On the Refresh Settings tab, click Initialize to initialize the persistent cache.
There are two options for initializing a persistent cache. Each is described below.
Create an LDIF File
If this is the first time you’ve initialized the persistent cache, choose this option. An LDIF formatted file is generated from the virtual view and then imported into the cache.
Using an Existing LDIF
If you’ve initialized the persistent cache before and the LDIF file was created successfully from the backend source(s) (and the data from the backend(s) has not changed since the generation of the LDIF file), then you can choose this option to use that existing file. The persisting of the cache occurs in two phases. The first phase generates an LDIF file with the data returned from the queries to the underlying data source(s). The second phase imports the LDIF file into the local RadiantOne Universal Directory store. If there is a failure during the second phase, and you must re-initialize the persistent cache, you have the option to choose the LDIF file (that was already built during the first phase) instead of having to re-generate it (as long as the LDIF file generated successfully). You can click browse and navigate to the location of the LDIF. The LDIF files generated are in <RLI_HOME>\<vds_server>\ldif\import.
If you have a large data set and generated multiple LDIF files for the purpose of initializing the persistent cache (each containing a subset of what you want to cache), name the files with a suffix of “_2”, “_3”…etc. For example, let’s say the initial LDIF file (containing the first subset of data you want to import) is named cacheinit.ldif. After this file has been imported, the process attempts to find cacheinit_2.ldif, then cacheinit_3.ldif…etc. Make sure all files are located in the same place so the initialization process can find them.
-
Click OK. The cache initialization process begins. The cache initialization is performed as a task and can be viewed and managed from the Tasks Tab in the Server Control Panel associated with the RadiantOne leader node. Therefore, you do not need to wait for the initialization to finish before exiting the initialization window.
-
The view(s) is now in the persistent cache. Queries are handled locally by RadiantOne and are no longer sent to the backend data source(s). Real-time cache refresh has been configured. For information about properties associated with persistent cache, please see Persistent Cache Properties.
Configuring Source Connectors Overview
Configuring connectors involves deciding how you want to detect changes from your backend(s). By default, all directory connectors and custom connectors (only custom connectors included in the RadiantOne install) are configured and started immediately without further configuration. For databases, configure the connector to use the desired change detection mechanism.
All connectors leverage the connection pooling settings defined from the Main Control Panel > Settings tab. In other words, the connector opens a connection to the data source to pick up changes and keeps the connection open so when the next interval passes a new connection does not need to be created.
Configuring Source Database Connectors
For database backends (JDBC-accessible), the change detection options are:
-
Changelog – This connector type relies on a database table that contains all changes that have occurred on the base tables (that the RadiantOne virtual view is built from). This typically involves having triggers on the base tables that write into the log/changelog table. However, an external process may be used instead of triggers. The connector picks up changes from the changelog table based on a specified interval which is 10 seconds by default.
-
Timestamp – This connector type has been validated against Oracle, SQL Server, MySQL, MariaDB, PostgreSQL, Snowflake, and Apache Derby. The database table must have a primary key defined for it and an indexed column that contains a timestamp/date value. This value must be maintained and modified accordingly for each record that is updated.
For Oracle databases, the timestamp column type must be one of the following: "TIMESTAMP", "DATE", "TIMESTAMP WITH TIME ZONE", "TIMESTAMP WITH LOCAL TIME ZONE".
For SQL Server database, the timestamp column type must be one of the following: "SMALLDATETIME", "DATETIME", "DATETIME2"
For MYSQL or MariaDB databases, the timestamp column type must be one of the following: "TIMESTAMP", "DATETIME"
For PostgreSQL databases, the timestamp column type must be one of the following: "TIMESTAMP", "timestamp without time zone” (equivalent to timestamp), “TIMESTAMPTZ”, “timestamp with time zone” (equivalent to timestamptz)
For Snowflake, the timestamp column type must be: TIMESTAMPNTZ
For Derby databases, the timestamp column type must be: "TIMESTAMP"
The DB Timestamp connector leverages the timestamp column to determine which records have changed since the last polling interval. This connector type does not detect delete operations. If you have a need to detect and propagate delete operations from the database, you should choose a different connector type like DB Changelog or DB Counter.
-
Counter - This connector type is supported for any database table that has an indexed column that contains a sequence-based value that is automatically maintained and modified for each record that is added/updated. This column must be one of the following types: BIGINT, DECIMAL, INTEGER, or NUMERIC. If DECIMAL or NUMERIC are used, they should be declared without numbers after the dot: DECIMAL(6,0) not as DECIMAL(6,2). The DB Counter connector leverages this column to determine which records have changed since the last polling interval. This connector type can detect delete operations as long as the table has a dedicated “Change Type” column that indicates one of the following values: insert, update, delete. If the value is empty or something other than insert, update, or delete, an update operation is assumed.
WarningIf none of these options are useable with your database, use a periodic cache refresh instead of real-time.
DB Changelog
RadiantOne can generate the SQL scripts which create the configuration needed to support the DB Changelog Connector. The scripts can be generated in the Main Control Panel. The following scripts are generated.
-
create_user.sql – Reminds you to have your DBA manually create a user account to be associated with the connector.
-
create_capture.sql - Creates the log table and the triggers on the base table.
-
drop_capture.sql - Drops the triggers and the log table.
Note: for some databases the file is empty.
- drop_user.sql - Drops the log table user and schema.
Note: for some databases the file is empty.
Connector Configuration
This section describes generating and executing the scripts in the Main Control Panel. The following steps assume the database backend has a changelog table that contains changed records that need to be updated in the persistent cache. The changelog table must have two key columns named RLICHANGETYPE and RLICHANGEID. RLICHANGETYPE must indicate insert, update or delete, dictating what type of change was made to the record. RLICHANGEID must be a sequence-based, auto-incremented INTEGER that contains a unique value for each record. The DB Changelog connector uses RLICHANGEID to maintain a cursor to keep track of processed changes.
To configure DB Changelog connector:
These instructions assume you want to apply the SQL scripts immediately and you already have a user account in the database to use for the connector.
- From the Main Control Panel > Directory Namespace Tab, select the configured persistent cache branch below the Cache node.
- On the right side, select the Refresh Settings tab.
- When the Real-time refresh type is selected, the connectors appear in a table below. Select a connector and click Configure.
- Select DB Changelog from the Connector Type drop-down list.
5.Enter the log table name using the proper syntax for your database (e.g. <USER>.<TABLE>_LOG). If you used RadiantOne to generate the SQL scripts for configuring the changelog components in the database, you can view the scripts to see the exact table name. Otherwise, contact your DBA for the log table name.
Change the value for this property only if you are creating the log table manually and the capture connector does not calculate the log table name correctly. Be sure to use the correct syntax if you change the value.
- Indicate the user name and password for the connector’s dedicated credentials for connecting to the log table. If you do not have the user name and password, contact your DBA for the credentials. An example is shown below.
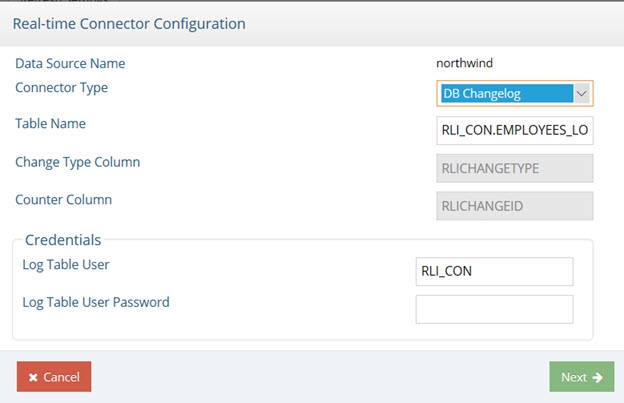
Figure 2.9: DB Changelog Connector Configuration
-
Click Next.
-
When the connector has been configured, click Next again.
-
Select Apply Now. Click Next.
NoteSelecting Apply Now creates and executes the SQL scripts. If you choose to apply later, the scripts can be downloaded to be reviewed and applied by the DBA directly on the database server.
-
Click Next and then click Finish.
-
After all connectors are configured, click Save.
The Execute DB Configure Scripts and Execute DB Deconfigure Scripts buttons become available when you finish configuring the connector. Execute DB Configure Scripts runs create_capture.sql. Execute DB Deconfigure Scripts runs drop_capture.sql. The location that RadiantOne looks for these scripts in cannot be changed.
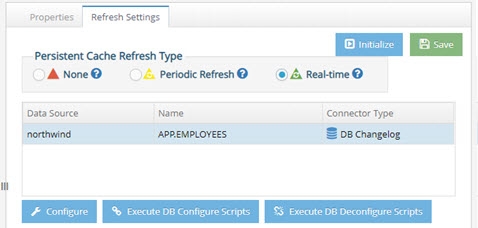
Figure 2.10: The Execute DB Configure and Deconfigure buttons
- Go to Main Control Panel > PCache Monitoring tab to start connectors, configure connector properties and manage and monitor the persistent cache refresh process.
If you make changes to the DB Changelog Connector configuration, restart the connector on the PCache Monitoring tab. Select the icon representing the database backend and click Stop. Then click Start to restart it.
Log Table Name Syntax
Proper syntax for the Log Table Name must include both the schema name and the table name separated with a period. Values for this property may contain quote marks as required by the database. In most cases, the double quote mark (“) is used, but some databases use a single quote (‘) or back quote (`). The following examples explain the property’s syntax and usage.
Example 1:
For Postgres, if the schema is rli_con, and log table name is test_log, the property should be one of the following.
By default, Postgres uses lower-case table names.
rli_con.test_log or with optional quoting: "rli_con"."test_log"
Example 2:
For SQL Server, if the schema is RLI_CON, and log table name is TEST_LOG, the property should be one of the following.
By default, many databases, including SQL Server, use upper-case table names.
RLI_CON.TEST_LOG
Or with optional quoting:
"RLI_CON"."TEST_LOG"
If this name is the same as the log name in the database, leave the property empty.
Example 3:
If schema and/or table name contain mixed-case characters, they must be quoted. For example, if the schema is Rli_Con, and log table name is Test_Log, the property should be as follows.
"Rli_con"."Test_log"
DB Timestamp
The following steps assume your backend database table has a primary key defined and contains a timestamp column. The timestamp column name is required for configuring the connector. The timestamp column database types supported are described in the Database Connectors section.
This connector type does not detect delete operations. If you need to detect delete operations from the database, you should choose a different connector type.
- From the Main Control Panel > Directory Namespace Tab, select the configured persistent cache branch below the Cache node.
- On the right side, select the Refresh Settings tab.
- When the Real-time refresh type is selected, the connectors appear in a table below. Select a connector and click Configure.
- Select DB Timestamp from the Connector Type drop-down list.
- Indicate the column name in the database table that contains the timestamp. An example is shown below.

Figure 2.11: DB Timestamp Connector Configuration
- Click OK.
- After all connectors are configured, click Save.
- The connectors are started automatically once they are configured.
- Go to Main Control Panel > PCache Monitoring tab to configure connector properties and manage and monitor the persistent cache refresh process.
If you need to make changes to the timestamp column name, manually restart the connector and reset the cursor. This can be done from the PCache Monitoring tab. Select the icon representing the database backend and click Stop. Then click Start to restart it. Then click Reset Cursor.
DB Counter
The following steps assume your database backend table contains an indexed column that contains a sequence-based value that is automatically maintained and modified for each record that is added, updated or deleted. The DB Counter connector uses this column to maintain a cursor to keep track of processed changes. The counter column database types supported are described in the Database Connectors section.
- From the Main Control Panel > Directory Namespace Tab, select the configured persistent cache branch below the Cache node.
- On the right side, select the Refresh Settings tab.
- When the Real-time refresh type is selected, the connectors appear in a table below. Select a connector and click Configure.
- Select DB Counter from the Connector Type drop-down list.
- Enter a value in the Change Type Column field. This value should be the database table column that contains the information about the type of change (insert, update or delete). If the column doesn’t have a value, an update operation is assumed.
- Enter the column name in the database table that contains the counter. An example is shown below.
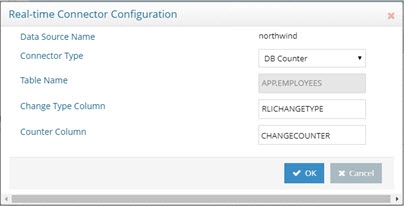
Figure 2.12: DB Counter Connector Configuration
-
Click OK.
-
After all connectors are configured, click Save.
-
The connectors are started automatically once they are configured.
-
Go to Main Control Panel > PCache Monitoring tab to configure connector properties and manage and monitor the persistent cache refresh process.
If you need to make changes to the Counter Column name, manually restart the connector and reset the cursor. This can be done from the PCache Monitoring tab. Select the icon representing the database backend and click Stop. Then click Start to restart it. Then click Reset Cursor.
Database Connector Failover
This section describes the failover mechanism for the database connectors.
The backend servers must be configured for multi-master replication. Please check the vendor documentation for assistance with configuring replication for your backends.
The database connectors leverage the failover server that has been configured for the data source. When you configure a data source for your backend database, select a failover database server from the drop-down list. The failover server must be configured as a RadiantOne data source. See the screen shot below for how to indicate a failover server for the Data Sources from the Main Control Panel.

Figure 2.14: Configuring Failover Servers for the Backend Database
If a connection cannot be made to the primary server, the connector tries to connect to the failover server configured in the data source. If a connection to both the primary and failover servers fails, the retry count goes up. The connector repeats this process until the value configured in Max Retries on Connection Error is reached. There is no automatic failback, meaning once the primary server is back online, the connector doesn’t automatically go back to it.
Re-configuring Database Connectors
By re-configuring the connector, you can change the connector type.
The connector can be re-configured from the Main Control Panel > Directory Namespace Tab. Navigate below the Cache node and select the persistent cache branch configured for auto-refresh. On the right side, select the Refresh Settings tab. Select the connector you want to re-configure and choose Configure.
To change the connector user password, for a connector currently using DB Changelog, enter the user name and password in the Credentials section.
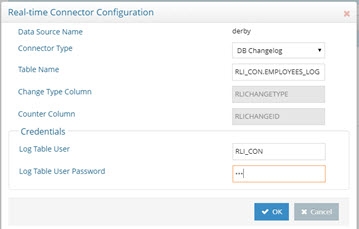
Figure 2.15: Editing DB Changelog Connector Configuration
To change the detection mechanism from DB Changelog to another method, select the type from the Connector Type drop-down menu. Enter values as needed for the properties specific to the new connector type and click Next. Click Next in the confirmation window to confirm that you want the connector reconfigured. Click Next to confirm that the connector has been reconfigured. Click Finish.
Configuring Source Directory Connectors
For directory backends (LDAP-accessible including RadiantOne Universal Directory and Active Directory), the default connectors are configured and started automatically. Go to Main Control Panel > PCache Monitoring tab to configure connector properties and manage and monitor the persistent cache refresh process.
If you are using a persistent cache on a proxy view of a local RadiantOne Universal Directory store, or a nested persistent cache view (a cached view used in another cached view), the connector type is noted as HDAP Trigger. This is a special trigger mechanism that publishes the changes directly into the queue to automatically invoke the refresh to all associated persistent cache layers. This change detection mechanism doesn’t require a connector process (or agents). If a RadiantOne service is virtualizing an external (non-local) RadiantOne Universal Directory store, and a persistent cache is configured for the view, this is considered an “LDAP backend” and the refresh connector can be configured for either changelog or persistent search (whatever is enabled/supported on the remote RadiantOne server) as described below.
LDAP Directories
For LDAP backends that support both Changelog and Persistent Search, you can configure the connector from the Main Control Panel -> Directory Namespace Tab. Navigate below the Cache node and select the persistent cache branch configured for auto-refresh. On the right side, select the Refresh Settings tab. Select the connector you want to configure and choose Configure. Choose either the LDAP option (for Changelog) or Persistent Search and click OK.
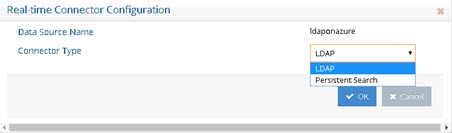
Figure 2.16: LDAP Directory Connector Types
Changelog - the connector leverages a changelog that has been enabled on the backend directory. The connector picks up changes from the cn=changelog naming context based on a polling interval. The changelog must be enabled in the backend directory. Please check with your directory vendor for instructions on how to enable the changelog.
Persistent Search - Any LDAP directory that offers a persistent search mechanism can use the Persistent Search connector type. Novell eDirectory is an example of an LDAP source that supports persistent search. Others include Red Hat Directory, IBM TDS, RadiantOne Universal Directory and CA Directory. The connector issues a persistent search and gets notified by the directory server when information changes. If the connector is shut down (either deliberately or due to failure), the delete operations that occurred in the directory are lost. Once the connector is back online there is no way to detect the delete operations that occurred while it was down. The only exception to this is for IBM TDS directories. It stores deleted entries and the capture connector is able to read them, and based on timestamp, determine if the change occurred while the connector was offline.
Active Directory
There are three change detection mechanisms: USNChanged, DirSync and Hybrid. If you are virtualizing and detecting changes from a Global Catalog, then you must use the USNChanged changed connector because the DirSync and Hybrid connectors cannot detect change events on sub-domains.
The flowchart below helps to decide which change detection mechanism to use.

Figure 2.17: Selecting a Active Directory Change Detection Mechanism
The Active Directory DirSync - the capture connector retrieves changes that occur to entries by passing a cookie that identifies the directory state at the time of the previous DirSync search. The first time the DirSync capture connector is started, it stores a cookie in a cursor file. At the next polling interval, the connector performs a DirSync search to detect changes by sending the current cookie. To use the DirSync control, the Bind DN connecting to the directory must have the DS-Replication-Get-Changes extended right, which can be enabled with the “Replicating Directory Changes” permission, on the root of the partition being monitored. By default, this right is assigned to the Administrator and LocalSystem accounts on domain controllers.
To detect delete events, the service account used by RadiantOne to connect to the backend Active Directory (configured in the connection string of the RadiantOne data source) must have permissions to search the tombstone objects. Usually, a member of the Administrators group is sufficient. However, some Active Directory servers may require a member of the Domain Admins group. Check with your Active Directory administrator to determine the appropriate credentials required.
If you are virtualizing and detecting changes from a Global Catalog, then you must use the Active Directory USNChanged changed connector because the DirSync connector cannot detect change events on sub-domains.
The Active Directory USNChanged capture connector keeps track of changes based on the uSNChanged attribute for the entry. Based on a configured polling interval, the connector connects with the user and password configured in the connection string/data source and checks the list of changes stored by Active Directory. The connector internally maintains the last processed change number (uSNChanged value) and this allows for the recovery of all changes that occur even if the connector is down (deliberately or due to failure).
If capturing the sequence of events is critical, use the DirSync connector instead of USNChanged because it processes events in the order in which they occur instead of prioritizing and processing inserts and updates before deletes.
By default, the connector is set to DirSync. To change, select the connector in the table and click Configure. Then select the desired change detection method from the drop-down list.
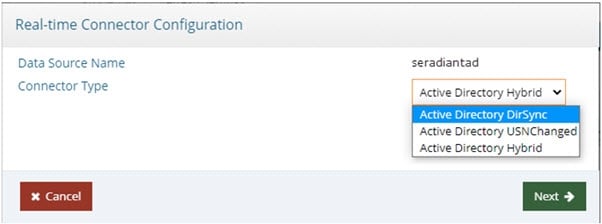
Figure 2.18: Active Directory Connector Type Configuration
The Active Directory hybrid capture connector uses a combination of the uSNChanged and DirSync change detection mechanisms. The first time the connector starts, it gets a new cookie and the highest uSNchanged number. When the connector gets a new change (modify or delete), it makes an additional search using the DN of the entry and fetches the entry from AD. The fetched entry contains the uSNChanged attribute, so the connector updates the cursor values for both for the cookie and the last processed uSNchanged number.
If you are virtualizing and detecting changes from a Global Catalog, then you must use the Active Directory USNChanged changed connector because the Hybrid connector cannot detect change events on sub-domains.
When the connector restarts, uSNChanged detection catches the entries that have been modified or deleted while the connector was stopped. The LDAP search uses the last processed uSNChanged number to catch up. After the connector processes all entries, it requests a new cookie from Active Directory (not from the cursor) and switches to DirSync change detection.
RadiantOne Directory Stores
If you are using a persistent cache on a proxy view of a local RadiantOne Directory store, or a nested persistent cache view (a cached view used in another cached view), the connector type is noted as HDAP (trigger) automatically and cannot be changed. This is a special trigger mechanism that publishes changes directly into the queue to invoke the persistent cache refresh.
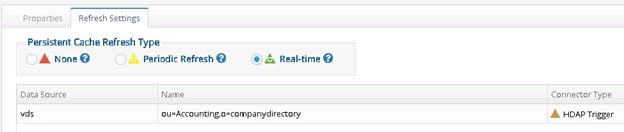
Figure 2.19: HDAP Trigger Connector Type
Connector properties can be edited from the Main Control Panel > PCache Monitoring tab. Click the icon representing the source in the topology to display the configuration section and view/edit properties.
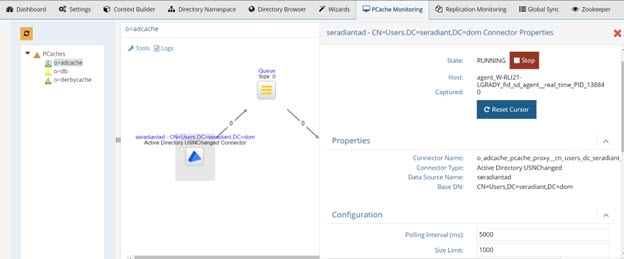
Figure 2.19: Connector Properties
Directory Connector Failover
This section describes the failover mechanism for the LDAP, Persistent Search and Active Directory connectors.
The backend servers must be configured for multi-master replication. Please check the vendor documentation for assistance with configuring replication for your backends.
The directory connectors leverage the failover servers that have been configured for the data source. When you configure a data source for your backend directory, you need to indicate the list of failover servers in order of priority. When the connector fails over, it uses the failover servers in the order they are listed. See the screen shot below for how to indicate a failover server for the Data Sources from the Main Control Panel.
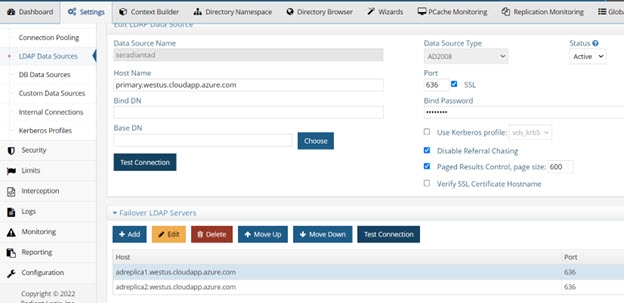
Figure 2.21: Configuring Failover Servers for the Backend Directory
If a connection cannot be made to the primary server and the maximum number of retry attempts has been exhausted, the connector connects to the failover servers in the order they are listed. There is no automatic failback, meaning once the primary server is back online, the connector doesn’t automatically go back to it.
This failover mechanism is supported for Active Directory, OpenDJ, Oracle Directory Server Enterprise Edition (Sun Directory v7), Oracle Unified Directory (OUD). In addition, any LDAP directory implementing cn=changelog and replicationCSN attribute or the persistent search control is also supported.
When the Active Directory DirSync connector fails over to another DC replica, the current cursor (cookie) is used. The connector may receive all objects and attributes from the replica instead of just the delta from its last request. Therefore, you may notice the number of entries published by the connector is more than you were expecting. This behavior is dictated by the Active Directory server and is out of the control of the connector. Keep this in mind when you define the Max Retries and Retry Intervals for the connector properties. The smaller the numbers of retries, the higher the chance the connector will fail over and possibly receive all objects and attributes (a full sync) from the domain controller.
For the Active Directory USNChanged connector, the failover logic leverages the Active Directory replication vectors [replUpToDateVector], and the failover servers configured at the level of the RadiantOne data source associated with Active Directory, to determine which server(s) the connector switches to in case of failure. Since the replication vector contains all domains, in addition to some possibly retired domains, the connector narrows down the list of possible failover candidates to only the ones listed as failover servers in the RadiantOne data source associated with the Active Directory backend. If there are no failover server defined for the data source, all domains in the replication vector are possible candidates for failover.
When defining the RadiantOne data source associated with Active Directory, do not use Host Discovery or Load Balancers. You must use the fully qualified machine names for the primary server and failover servers. Do not use IP addresses. Also, it is highly recommended that you list your desired failover servers at the level of the data source. Not only does this make the failover logic more efficient, but it also avoids delays in synchronization.
[replUpToDateVector] definition: The non-replicated attribute replUpToDateVector is an optional attribute on the naming context root of every naming context replica. If this vector is unavailable, the connector is suspended.
The ReplUpToDateVector type is a tuple with the following fields:
-
uuidDsa: The invocation ID of the DC that assigned usnHighPropUpdate.
-
usnHighPropUpdate: A USN at which an update was applied on the DC identified by uuidDsa.
-
timeLastSyncSuccess: The time at which the last successful replication occurred from the DC identified by uuidDsa; for replication latency reporting only.
[replUpToDateVector] example:
01ca6e90-7d20-4f9c-ba7b-823a72fc459e @ USN 2210490 @ Time 2005-08-21 15:54:21
1d9bb4b6-054a-440c-aedf-7a3f28837e7f @ USN 26245013 @ Time 2007-02-27 10:17:33
24980c9d-39fa-44d7-a153-c0c5c27f0577 @ USN 4606302 @ Time 2006-08-20 23:33:09
At run-time, the connector retrieves the entire list of servers defined in the replication vector and reduces the number of possible failover candidates based on failover servers defined in the RadiantOne data source. The list of potential failover servers is stored at each polling interval. When the current server fails, the connector decides to switch to the closest candidate by selecting the server with the maximum timestamp from the up-to-dateness vector. The capture connector’s cursor will be assigned the value from the up-to-dateness vector for the failover server. If the closest candidate fails as well, the connector tries with a second closest candidate and so on.
Due to the lack of Active Directory replication for the USNChanged attribute, some changes could be missed or replayed on failover.
For the AD Hybrid connector, the failover process starts when the number of exceptions exceeds either the Maximum Retries on Error or Maximum Retries on Connection Error value. The failover servers are specified in the data source associated with Active Directory. The Active Directory up-to-date vector is used to determine the failover server and the value of the new cursor. If the up-to-date vector is unavailable from the current server, failover is not possible. If this happens, verify that AD replication is correctly configured. After the failover server is found, uSNChanged detection catches the entries that have been modified or deleted since the connector’s failure. The LDAP search uses the last processed uSNChanged number to catch up.
Due to the lack of Active Directory replication for the USNChanged attribute, some changes could be missed or replayed on failover.
After the connector processes all entries, it requests a new cookie from Active Directory and switches to DirSync change detection.
Configuring Source Custom Connectors
The following custom data sources support Real-time persistent cache refresh. For all other custom data sources, use a periodic cache refresh.
-
Any source that supports SCIM v1 or v2 (e.g. scimclient and scimclient2 custom data sources)
-
Azure Active Directory (e.g. default mgraph custom data source)
-
Okta Universal Directory (e.g. default oktaclient custom data source)
The custom connectors are configured and started automatically. Go to Main Control Panel > PCache Monitoring tab to configure connector properties and manage and monitor the persistent cache refresh process. Click the icon representing the custom data source in the topology to display the configuration section and view/edit properties.

Figure 2.22: Custom Connector Properties
Custom connectors don’t have built-in failover logic. The web service target must handle failover and this is typically achieved with a web server/HTTP load balancer.
Connector Properties
The following properties are for real-time persistent cache refresh capture connectors. Not all properties are applicable for every type of backend. The description indicates the type of backend the property is used for.
Property | Description |
|---|---|
Polling Interval | This property indicates the amount of time (in milliseconds) the connector should wait before querying the source to check for changes. |
Size Limit | This property indicates the number of entries the connector collects from the source in a single request. However, even if the connector picks up multiple entries, they are processed and published to the queue one at a time. |
Log Level | Log Level – OFF: Used to turn logging off. |
Max Retries On Error | If the connector is unable to connect to the source to pick up changes for any reason other than a connection error, it tries to reconnect. Maximum Retries on Error is the total number of times the connector tries reconnecting. The frequency of the reconnect attempt is based on the Retry Interval on Error property. After all attempts have been tried, the connector failover logic is triggered. If there are no backends available to connect to, the agent automatically redeploys the connector until a connection to the backend can be made. |
Retry Interval on Error | Used in conjunction with the Max Retries on Error property. This is the amount of time (in milliseconds) the connector waits before it attempts to pick up changes from the source after an error has occurred. |
Max Retries on Connection Error | For Database Connectors - If the connector is unable to connect to the primary backend server, it tries to connect to the failover server. If the connector cannot connect to the primary or failover servers because of a connection error, it tries to connect again later. Maximum Retries on Connection Error is the total number of times the connector tries reconnecting. A failed attempt to connect to both the primary and failover server is considered a single retry. The frequency of the reconnect attempt is based on the Retry Interval on Connection Error property. If there are no backends available to connect to, the agent automatically redeploys the connector until a connection to the backend can be made. |
Retry Interval on Connection Error | Used in conjunction with the Max Retries on Connection Error property. This is the amount of time (in milliseconds) the connector waits before trying to establish a connection to the source if there was a connection problem during the previous attempt. |
LDAP Filter | To further condition the entries that are published, you can indicate the desired criteria in the LDAP Filter property. This is a post filter, used to qualify which entries are published by the connector. You must enter a valid LDAP filter in the property. |
Excluded Branches | To further condition the entries that are published, you can indicate branch(es) to exclude. In the Excluded Branches property, enter one or more suffixes associated with entries that should not be published in the message by the connector. Click “Enter” to accept the value and to be able to enter another suffix. You can use the “x” next to the suffix to remove it. |
Included Branches | To further condition the entries that are published, you can indicate branch(es) to include. In the Included Branches property, enter one or more suffixes associated with entries that should be published by the connector. Click “Enter” to accept the value and to be able to enter another suffix. You can use the “x” next to the suffix to remove it. |
SQL Filter | SQL filter is a post filter used to evaluate entries captured by the connector. Only changes that match the filter are published by the connector. |
Force Sequential Counters (true/false) | This property accepts a value of true or false and dictates how the connector treats entries it picks up from the LOG table that have non-sequential change IDs. The default is true meaning that if the connector detects a non-sequential change ID for an entry in the LOG table, it behaves as if there is an error (non-connection error) and the retry logic based on the Max Retries on Error and Retry Interval on Error properties takes effect. Sometimes rows in the log table are not written in the order of the change ID, and if the connector doesn’t wait for the entries to have sequential IDs, some changes could be missed. The connector waits for the length of time specified in the Retry Interval on Error property and then tries to get the changed entries in the database again. After the maximum number of retries (indicated in the Max Retries on Error property) is exhausted, if it still detects non-sequential change IDs, the connector stops. Set “Force Sequential Counters” to false before restarting the connector to have the connector ignore non-sequential change IDs. |
Processing Delay | This property can be used if there is a need for a delay in the processing of changes by the connector. For example, if there are two or more processes that update the source table at the same time, and they take about 2 minutes each to run, the processing delay can be set at anywhere between 4-6 minutes. This delays the processing and makes sure the connector captures all changes coming from both processes. |
Skip catch-up process (true/false) | If this option is set to false, when the connector starts, it tries to pick up all changes that happened since the last time it successfully processed any changes (this information is maintained in the connector’s cursor file). This is based on changenumber. If this option is set to true, the connector sends out only the changes that happen after it has started. All changes that happened while the connector was stopped are ignored. |
Switch to Primary Server (in Polling Intervals) | This option, working in conjunction with the Polling Interval property, allows you to configure how often, if at all, the connector attempts to switch back to the primary server after failover. To configure the connector to attempt to switch to the primary server, set Switch to Primary Server to a value of 4 or greater. You can set the value to less than 4, but attempting to connect back to the primary server can be time consuming and therefore not recommended to do frequently. For example, if this value is set to 1, the connector makes an attempt every polling interval. If the Switch to Primary Server value is 3, the connector makes an attempt every third polling interval. |
Failover Algorithm [1-4] | This option is relevant for the LDAP changelog connector type. |



Resetting Connector Cursor – Detect New Only
Capture connectors use a cursor to maintain information about the last processed changes. This allows the connectors to capture only changes that have happened since the last time they checked for changes. When the real-time persistent cache refresh connectors start, they automatically attempt to capture all changes that have happened since the last time they checked. If the real-time persistent cache refresh process has been stopped for an extended period of time, you might not want them to attempt to capture all changes since the last time they checked. In this case, you can reset the cursor for the connector. From the Main Control Panel > PCache Monitoring tab, select the real-time refresh topology and the topology displays. Click the icon representing the capture connector and the Runtime details are displayed on the right. Click Reset Cursor to clear the cursor value and trigger the connector to behave as if it is the first time connecting to the source to collect changes.
Persistent Cache Properties
Once a persistent cache is configured, properties can be managed from the Main Control Panel > Directory Namespace tab > Cache node. Select the configured persistent cache branch and the properties are available on the right.
Non-indexed Attributes
If the Indexed Attributes list is empty, all attributes are indexed by default (except binary ones). Also, the following “internal” ones won’t be indexed either: "creatorsName", "createTimestamp", "modifiersName", "modifyTimestamp", "cacheCreatorsName", "cacheCreateTimestamp", "cacheModifiersName", "cacheModifyTimestamp", "uuid", "vdsSyncState", "vdsSyncHist", "ds-sync-generation-id", "ds-sync-state", "ds-sync-hist", "vdsSyncCursor", "entryUUID", "userpassword”. Any additional attributes that you do not want indexed should be added to the Non Indexed Attributes list on the Properties tab for the selected persistent cache branch.
If you change the non-indexed attributes, you must re-build the index. You can do this from the Properties tab by clicking Re-build Index.
Sorted Attributes
This is a comma-separated list of attributes to be used in association with Virtual List Views (VLV) or sort control configured for RadiantOne. These sorted indexes are managed internally in the persistent cache and kept optimized for sorting. They are required if you need to sort the search result or to execute a VLV query on the persistent cache branch.
If you need to support VLV, the VLV/Sort control must be enabled in RadiantOne. For details on this control, please see the RadiantOne System Administration Guide.
If you change the sorted attributes, you must re-build the index. You can do this from the Properties tab by clicking Re-build Index.
Encrypted Attributes
Attribute encryption protects sensitive data while it is stored in RadiantOne. You can specify that certain attributes of an entry are stored in an encrypted format. This prevents data from being readable while stored in persistent cache, backup files, and exported LDIF files. Attribute values are encrypted before they are stored in persistent cache, and decrypted before being returned to the client, as long as the client is authorized to read the attribute (based on ACLs defined in RadiantOne), is connected to the RadiantOne service via SSL, and not a member of the special group containing members not allowed to get these attributes (e.g. cn=ClearAttributesOnly,cn=globalgroups,cn=config). For details on this special group, please see the RadiantOne System Administration Guide.
Define a security encryption key from the Main Control Panel > Settings Tab > Security section > Attribute Encryption prior to configuring encrypted attributes. For steps on defining key generation, see the RadiantOne System Administration Guide.
On the Properties Tab for the selected persistent cache, enter a comma-separated list of attributes to store encrypted in the Encrypted Attributes property. Attributes listed in the Encrypted Attributes property are added to the Non-indexed attribute list by default. This means these attributes are not searchable by default. Indexing encrypted attributes is generally not advised as the index itself is less secure than the attribute stored in the persistent cache. However, if you must be able to search on the encrypted attribute value, it must be indexed. Only “exact match/equality” index is supported for encrypted attributes. To make an encrypted attribute searchable, remove the attribute from the list of nonindexed attributes and then click Re-build Index.
Extension Attributes
Extension Attributes are new attributes (meaning these attributes don’t exist anywhere yet) that are associated with a cached virtual entry. This is primarily used to accommodate the storage of application-specific attributes that you want to store locally as opposed to the backend(s) you are virtualizing. Extension attributes should be used as an alternative to Extended Joins in scenarios where the virtual view is stored in persistent cache and then needs replicated out to RadiantOne Universal Directory stores in other clusters.
Extension attributes are stored locally and RadiantOne handles the lifecycle of these attributes accordingly. Once a persistent cache is defined, list the attribute names (comma-separated) in the Extension Attributes property. The attribute names must be unique and not overlap with attributes coming from and being cached from existing backends. The example below has an extension attribute named lastLogin. Applications can write to this attribute and RadiantOne handles the write locally without delegating anything to the backend.
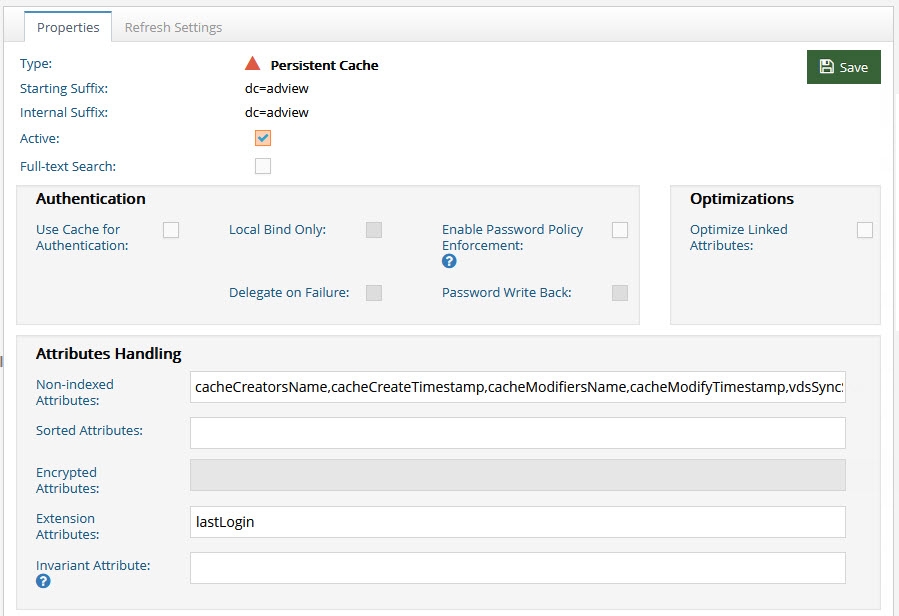
Figure 2.23: Extension Attributes for Persistent Cache
For consistency of the RadiantOne LDAP schema, define the extension attributes as part of the schema, generally associated with an auxiliary object class. For details on extending the schema, see the RadiantOne System Administration Guide.
Extension Attributes are replicated to other clusters in deployment scenarios where inter-cluster replication is enabled and a replica of a persistent cache is maintained as a RadiantOne Universal Directory store in the target cluster(s).
When using extension attributes for cached virtual views of LDAP directory backends, you must configure invariant attribute(s). See the following section for more details.
Invariant Attributes
To guarantee extension attributes are linked to their respective underlying entries and moved properly should modRDN/modDN events occur in the backend source, invariant attribute(s) must be defined. The invariant attribute is the unique identifier in the backend directory. Below are some invariant attributes used in common LDAP directories.
-
objectGUID (Active Directory)
-
entryUUID (Oracle Unified Directory, OpenDJ, unboundID)
-
nsUniqueID (Sun/ODSEE)
-
ibm-entryUUID (IBM)
-
UUID (RadiantOne Universal Directory)
For the example shown below, the persistent cached view is from an Active Directory backend. RadiantOne manages the lifecycle of the attribute named lastLogin and this attribute is stored directly in the cache. The invariant attribute is set to objectGUID which is the unique identifier for the users in the backend Active Directory. If the entry in the backend is moved, the invariant attribute ensures RadiantOne handles the move of the associated cached extension attributes properly.
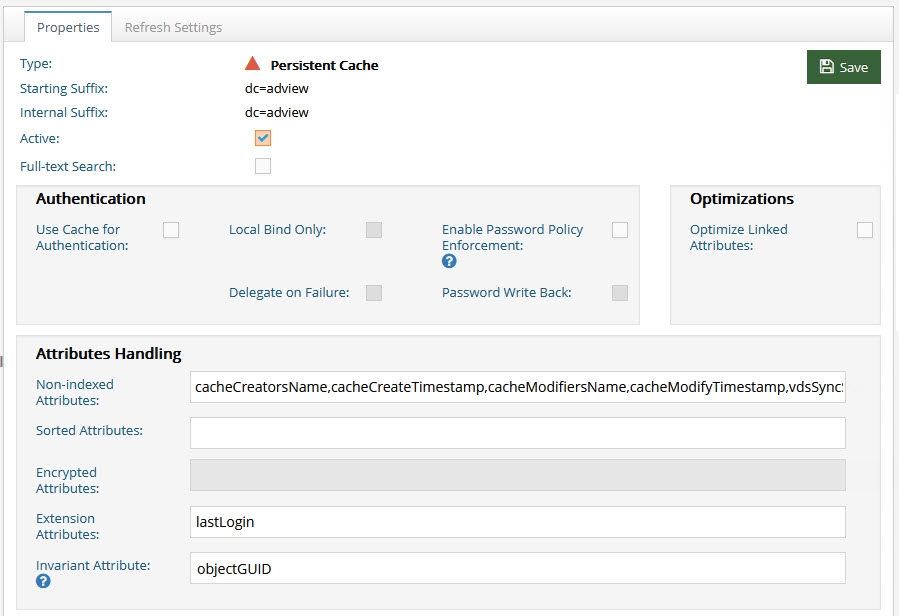
Figure 2.24: Invariant Attribute for Persistent Cache
Inter-cluster Replication
This option should be enabled if you want to support replication between this persistent cache branch and a RadiantOne Directory store in a different cluster.
If inter-cluster replication is enabled, a replication journal is used to store changes that happen on the persistent cache branch. The replication journal is associated with the default LDAP data source defined as replicationjournal and root naming context named cn=replicationjournal. The RadiantOne leader node in the cluster associated with the persistent cache, publishes changes into the replication journal. The RadiantOne leader nodes in all other clusters (that are configured for inter-cluster replication) pick up changes from the replication journal to update their local replica. Persistent caches usually only publish changes into the replication journal (for other RadiantOne Universal Directory replicas in other clusters). There are some cases where persistent cache can accept changes from other clusters.
Changes that haven’t been picked up from the replicationjournal for 3 days are automatically purged.
Accept Changes from Replicas
For limited use cases where the only type of modify operations that client applications perform is updates to existing entries (no adds or deletes), the persistent cache can subscribe to these events. If the persistent cache should process attribute updates from RadiantOne Universal Directory replicas in other clusters, enable the Accept Changes from Replicas option and list the acceptable attributes in the Updateable Attributes from Replicas property.
Persistent Cache stores can only accept modification operations from RadiantOne Universal Directory replicas. Add and delete operations are currently not supported. Therefore, proper ACLs should be configured for the RadiantOne Universal Directory replicas to prevent the addition and deletion of entries.
This is an advanced setting, consult with a Radiant Logic Solution Architect to get assistance on the needed architecture and usage.
Updateable Attributes from Replicas
A comma-separated list of attribute names that the persistent cache should accept changes for. Only changes made to these attributes are processed by the persistent cache. All other changes published in the replication journal from the RadiantOne Universal Directory replicas are ignored by the persistent cache. If an updateable attribute is associated with an extension attribute in the persistent cache, the attribute update is handled locally. If an updateable attribute is sourced from a backend data source, the update is forwarded to the appropriate backend and the cache image is refreshed after the backend update is successful. If the backend update fails, the current persistent cache image is considered the reference and is published to the replication journal to override the images in the RadiantOne Universal Directory replicas in all other clusters.
Persistent Cache stores can only accept modification operations from RadiantOne Universal Directory replicas. Add and delete operations are currently not supported. Therefore, proper ACLs should be configured for the RadiantOne Universal Directory replicas to prevent the addition and deletion of entries.
This is an advanced setting, consult with a Radiant Logic Solution Architect to get assistance on the needed architecture and usage.
Use Cache for Authentication
The default behavior of the RadiantOne service for processing bind requests for users located in a persistent cache branch is to delegate the credentials checking to the authoritative backend source. If the password in the backend is encrypted using one of the algorithms supported by RadiantOne, and the passwords are stored in the cache, you can configure the service to authenticate the user locally against the password in cache instead of delegating the credentials checking to the backend. To enable this behavior, check the Use Cache for Authentication option on the configured cache branch. This option is not applicable in scenarios where the passwords are not stored in the persistent cache. For an example use case where this option could be applicable, please see Authoritative Backends Inaccessible by All Sites.
By default, if the Use Cache for Authentication option is enabled and the entry in persistent cache has a password, RadiantOne checks the password against the local value and the user is authenticated or not based on this comparison. If the entry in persistent cache doesn’t have a password, RadiantOne delegates the credentials checking to the backend data source. There are two options to override this default behavior: Local Bind Only or Delegate on Failure.

Figure 2.25: Authentication Options
Each option is described in more details below.
-
Local Bind Only – If this option is enabled and the user entry in cache either has no password or the bind fails, RadiantOne does not delegate the credentials checking to the backend. It determines if the user authentication fails based on the local comparison.
-
Delegate on Failure – If this option is enabled and the user entry in cache has a password but the local checking fails, RadiantOne delegates the credentials checking to the backend. If the credentials checking fails against the backend, an unsuccessful bind response is returned to the client. If the credentials checking succeeds against the backend, a successful bind response is returned to the client.
-
Enable Password Policy Enforcement - If you are storing user passwords in cache and you are using the cache for authentication, you can also choose to have RadiantOne enforce password policies (as opposed to delegating password checking to the backend directory and having it enforce password policies). Enable this option and then define the password policy to enforce. For details on password policies, see the RadiantOne System Administration Guide.
-
When you enable the password policy enforcement on a persistent cache, the userPassword attribute is automatically added to the Extension Attribute property and you have the option to enable Password Write Back. If Password Write Back is enabled, and a modify request for the password is sent to RadiantOne, it tries to update the password in the backend. In some circumstances, having two levels of password policies can result in inconsistencies between the cache image and the underlying backend(s). These circumstances are outlined in the table below.
Password Change Event | Password Writeback Enabled? | Expected Behavior |
|---|---|---|
Password update via a Modify Request sent to RadiantOne | No | The password is updated in the persistent cache if it complies with the persistent cache password policy. Otherwise the password update fails. |
Password update via a Modify Request sent to RadiantOne | Yes | The password update is sent to the backend. If the password update fails in the backend, the password in the persistent cache is not updated. If the password update succeeds in the backend, the password is updated in the persistent cache. |
Password is updated directly in the backend (outside of RadiantOne) | N/A | Through the persistent cache refresh process, the password is updated in the persistent cache. If the account was locked in the persistent cache due to a password policy enforced at the cache layer, it will be unlocked by the cache refresh process after a successful password update in the backend. Password strength defined in the persistent cache password policy is not enforced since the password change originated from the backend. |
Active
Check the Active option if you want to Activate this naming context. Uncheck the Active option to deactivate the cache. If a persistent cache is deactivated, RadiantOne issues queries to the backend(s) when processing client requests.
Full-text Search
Persistent cache branches can support full text searches. This offers additional flexibility for clients as they can search data in the RadiantOne namespace based on text (character) data. These types of searches are no longer linked to specific attributes as the characters requested could be found in any attribute value. An entry is returned if any attribute in the entry contains the character string(s) requested by the client.
Clients issue full text searches similar to the way they issue LDAP searches. The only difference is the filter contains (fulltext=<value>) where <value> would be the text they are interested in. As an example, if a client was interested in the text John Doe as an exact phrase, the search filter sent to RadiantOne would be (fulltext= “John Doe”) where the phrase is encapsulated in double quotes. If the phrase in the filter is not encapsulated in double quotes it means the client wants any entries that have attribute values that contain the character string John OR Doe.
The part of the filter that contains the piece related to the full text search can also be combined with other “standard” LDAP operators. As an example, a filter could be something like (&(uid=sjones)(fulltext=”John Doe”)). This would return entries that contain a uid attribute with the value sjones AND any other attribute that contains the exact character string John Doe.
If you want the persistent cache to support full text searches, check the Full-Text Search option and click Save. If you add the support for full text searches, click Re-build Index.
Optimize Linked Attributes
Linked attributes are attributes that allow relationships between objects. A typical example would be isMemberOf/uniqueMember for user/groups objects. A group has members (uniqueMember attribute) which is the forward link relationship. Those members have an isMemberOf attribute which is the back link (to the group entry) relationship. Other examples of linked attributes are:
manager/directReports
altRecipient/altRecipientBL
dLMemRejectPerms/dLMemRejectPermsBL
dLMemSubmitPerms/dLMemSubmitPermsBL
msExchArchiveDatabaseLink/msExchArchiveDatabaseLinkBL
msExchDelegateListLink/msExchDelegateListBL
publicDelegates/publicDelegatesBL
owner/ownerBL
The most common back link/forward link relationship is between group and user objects. A list of groups a user is a member of can be calculated automatically by RadiantOne and returned in the membership attribute of the user entry. The most common back link attributes are in the drop-down list. However, you can manually enter any attribute name you want. This is configured on the Main Control Panel, click Settings > Interception > Special Attributes Handling > Linked Attributes setting (on the right).
If the Target Base DN (back link attribute location) and the Source Base DN (forward link attribute location) in the Linked Attributes setting is a persistent cached branch, the computation of the references can be optimized in order to return client requests for the back link attribute at high speed. To enable this optimization, follow the steps below.
If your linked attributes are for users and groups (both branches located in persistent cache), and you enable the Optimize Linked Attributes setting, and must support nested groups, only one user location per persistent cache store is supported. For example, in the Linked Attributes setting, having a Target Base DN location configured for ou=people1,dc=myhdap and ou=people2,dc=myhdap (both in the same dc=myhdap persistent cache store) is not supported. In this case, you should configure a single user location as dc=myhdap as a shared parent for both containers.
It is assumed you have configured and initialized your persistent cache, and configured the Linked Attributes in Special Attributes Handling. If you have not, please do so prior to continuing with the steps below.
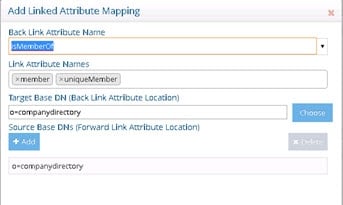
Figure 2.29: Back Link Attribute Name in Special Attribute Handling
-
Select the Optimize Linked Attributes option on the Properties tab for the selected persistent cache branch on the Main Control Panel > Directory Namespace tab > Cache section. The defined linked attribute is added to the Extension Attributes List for the persistent cache.
-
Click Save.
-
You can either rebuild the index, or reinitialize the persistent cache. Click Re-build Index or Initialize. The back link attribute is always returned to clients even when not requested unless Hide Operational Attributes is enabled in RadiantOne (in which case it is only returned when a client explicitly requests it). For details on the Hide Operational Attributes setting, please see the RadiantOne System Administration Guide.
If a persistent cache has optimizations associated with it, deactivating it will interfere with queries associated with the linked attributes and they will not return properly. If you no longer need a cache, delete it instead of deactivating it.
Persistent Cache Universally Unique Identifier (UUID)
The Universally Unique Identifier (UUID) attribute is a reserved, internal attribute that is assigned to each entry and can guarantee uniqueness across space and time.
When adding entries into a persistent cache (LDAP ADD operations) from an LDIF file, if there are UUID attributes they are ignored by RadiantOne during import. RadiantOne generates a unique value for each entry based on the specifications in RFC 4122.
When initializing with an LDIF file (LDIF INIT), if the entry has a UUID attribute, RadiantOne keeps it. If the entry does not have a UUID attribute, RadiantOne generates a unique value for each entry based on the specifications in RFC 4122.
UUID is an operational attribute meaning that if a client wants this attribute, they must explicitly ask for it in the search request sent to RadiantOne.
When exporting a persistent cache store to an LDIF file, you have the option to export the UUID attribute or not. The UUID attribute should be exported into LDIF if you plan on using this export to initialize a RadiantOne Universal Directory store, a replica for inter-cluster replication. Otherwise, the UUID attribute generally should not be exported. To export a persistent cache store and include the UUID attributes, check the Export for Replication option in the export window.
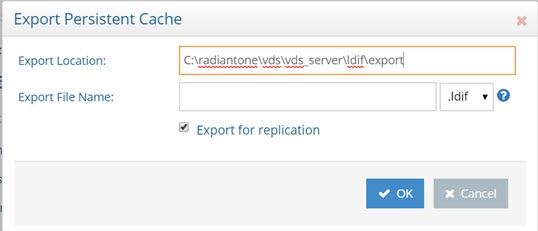
Figure 2.30: Export Persistent Cache
Managing the Persistent Cache
Re-initializing a Persistent Cache
Persistent cache should be re-initialized during off-peak hours, or during scheduled downtime, since it is a CPU-intensive process and during the initialization queries are delegated to the backend data sources which might not be able to handle the load.
Cache refresh connectors do not need to be stopped to re-initialize the persistent cache.
-
Deactivate any inter-cluster replication on the cached branch prior to re-initializing. To do so, navigate to the cached branch on the Main Control Panel > Directory Namespace Tab and on the right side, uncheck “Inter-cluster Replication”, then click Save. Click Yes to apply the changes to the server.
-
With the cached node selected, on the Refresh Settings tab, click Initialize.
-
Choose to either initialize the cache by creating an LDIF file or from an existing LDIF file. Typically, you would always use the default option which is to create an LDIF file. The only time you could choose to use an existing file is if you already have an up-to-date LDIF file containing all of the needed entries.
-
Click OK. A task is launched to re-initialize the persistent cache. The task can be monitored and managed from the Server Control Panel > Tasks Tab associated with the RadiantOne leader node.
-
Click OK to exit the initialization wizard.
-
Click Save in the upper right corner.
-
Re-enable Inter-cluster Replication that was deactivated in step 1.
Re-building Index
If the cache has already been initialized, and the attribute list for sorted indexes changes (new attributes need to be indexed or removed from the index), you must rebuild the index. From the Main Control Panel -> Directory Namespace Tab, select the persistent cache branch below the Cache node. On the Properties tab on the right side, click the Re-build Index button.
Exporting the Cache
Exporting the cache generates an LDIF formatted file from the cache contents. This can be useful if you want to replicate this cache image across multiple RadiantOne clusters. To export the cached branch, from the Main Control Panel -> Directory Namespace Tab, select the persistent cache branch below the Cache node. On the Properties Tab on the right side, click the Export button. Enter a name, select a type of file (LDIF or LDIFZ which is a zipped and encrypted file) and click OK. If you want to use this LDIF file to initialize a cache or Universal Directory store in another cluster, use the Main Control Panel > Settings Tab > Configuration > File Manager to browse to <RLI_HOME>/vds_server/ldif/export to download the file. Then, connect to the Main Control Panel in the target environment where you want to use the LDIF file and use the Settings Tab > Configuration > File Manager to navigate to <RLI_HOME>/vds_server/ldif/import to upload the LDIF file. When you initialize the cache in the target environment, browse to this location to locate the file to use for initialization.
If exporting to an LDIFZ file, a security key must be configured. This key is the same as the one used for attribute encryption. Any target server (persistent cache or RadiantOne Universal Directory store) where you want to import this LDIFZ file must use the same security key value. The security key is defined from the Main Control Panel > Settings Tab > Security > Attribute Encryption section. If an LDIFZ encryption key is defined, only the ldifz file type is available when exporting to LDIF from the Main Control Panel > Directory Browser tab.
Figure 2.31: Exporting an LDIFZ file
Testing Persistent Cache Refresh Process
To test the persistent cache refresh process, use an LDAP command line utility like the one described below. If the connectors are running, suspend them from the Main Control Panel > PCache Monitoring tab.
The ldapsearch utility offered in the Sun Resource Kit can be used to force a refresh of the persistent cache based on a specific DN. The command would look similar to the following:
ldapsearch -h 10.11.12.91 -p 2389 -D "cn=directory manager" -w "secret" -b "action=synchronizecache,customers=ALFKI,dv=northwind,o=vds" -s base (objectclass=*)
The above command refreshes the single entry identified by the DN of customers=ALFKI,dv=northwind,o=vds. If you want to refresh multiple entries with a single command, you can use a ONE LEVEL or SUBTREE scope. If you wanted to refresh all entries below dv=northwind, the command would be:
ldapsearch -h 10.11.12.91 -p 2389 -D "cn=directory manager" -w "secret" -b "action=synchronizecache,dv=northwind,o=vds" -s one (objectclass=*)
Each parameter of the command is described below.
-h is the RadiantOne server name or IP address.
-p is the LDAP port RadiantOne is listening on.
-D is the user to connect to RadiantOne as.
-w is the password for the user you are connecting with.
-b is the DN for the entry in the persistent cache that you want refreshed (if a base scope). If a one level, or sub tree scope is used, then -b is the starting point in the persistent cache to start refreshing from.
-s is the scope of the search which should be base, one or sub.
(objectclass=*) is the filter.
Modify the above command to match your requirement. Keep the following in mind.
-
Always connect to RadiantOne as the directory manager
-
Replace the DN with your own (always start with action=synchronizecache,)
To test, first modify the information in the underlying source. The persistent cache should not reflect any change. Next, execute the ldapsearch command mentioned above. Now, the persistent cache should reflect the new entry. Be sure to check all log files if the persistent cache did not get refreshed properly.
Logging Persistent Cache Refreshes
If the change log has been enabled for RadiantOne, then all changes affecting the persistent cache are logged there. Otherwise, all activity to the persistent cache is logged into a branch in the RadiantOne namespace with a root suffix of cn=cacherefreshlog. This branch only stores changes that affect persistent cache branches.
Logging of persistent cache changes into the cn=cacherefreshlog is always enabled and different log levels can be configured. The log level is set on the Main Control Panel > Settings Tab > Logs section > Changelog sub-section. Select the drop-down list next to the Persistent Cache Refresh Log option on the right side and choose a log level. The log levels are:
-
Error – logs only errors that occur when trying to refresh the persistent cache. This is the default.
-
Status – logs the status (and the DN that was refreshed) when refreshes are made to the persistent cache.
-
All – logs all refreshes to the persistent cache including the changes that occurred.
Entries remain in the cn=cacherefreshlog for a default of 3 days. This is configurable and defined in the Main Control Panel > Settings Tab > Logs section > Changelog sub-section, Changelog and Journal Stores Max Age property. This property is shared by the following internal stores.
-
cn=changelog
-
cn=cacherefreshlog
-
cn=replicationjournal
-
cn=localjournal
-
cn=tombstone
-
cn=clustermonitor
-
cn=queue
-
cn=dlqueue
Typically, if the changelog has been enabled then error log level is used for the persistent cache refresh log. For more information, please see Persistent Cache Log Setting in the RadiantOne System Administration Guide.
Detecting Persistent Cache Update Errors
If an entry in the persistent cache fails to be updated, the entry in the cache refresh log is tagged with a status attribute of 2.
An example of a failed cache refresh log entry can be seen in the figure below.
Figure 2.32: Persistent Cache Refresh Log Entry
If the problem resulting in the update error has been fixed, you can manually reissue the update request with a base search on the entry using the targetDN attribute in the persistent cache refresh log. Using the example shown above, the entry in persistent cache is Employee=1,Category=employees,dc=csaa. Therefore, the command to refresh this entry in cache would look similar to the following:
ldapsearch -h 10.11.12.91 -p 2389 -D "cn=directory manager" -w "secret" -b "action=synchronizecache,Employee=1,Category=employees,dc=csaa" -s base (objectclass=*)
If there are many failed entries in the persistent cache refresh log, meaning that the cache image is significantly different than the backends, it might be more efficient to reinitialize the persistent cache as opposed to trying to fix the failed updates one at a time.
Deleting the Persistent Cache
To delete a persistent cache branch, uncheck the Active checkbox (on the Properties tab for the cached branch), then click Save to apply the changes to the server. Then click Delete.
